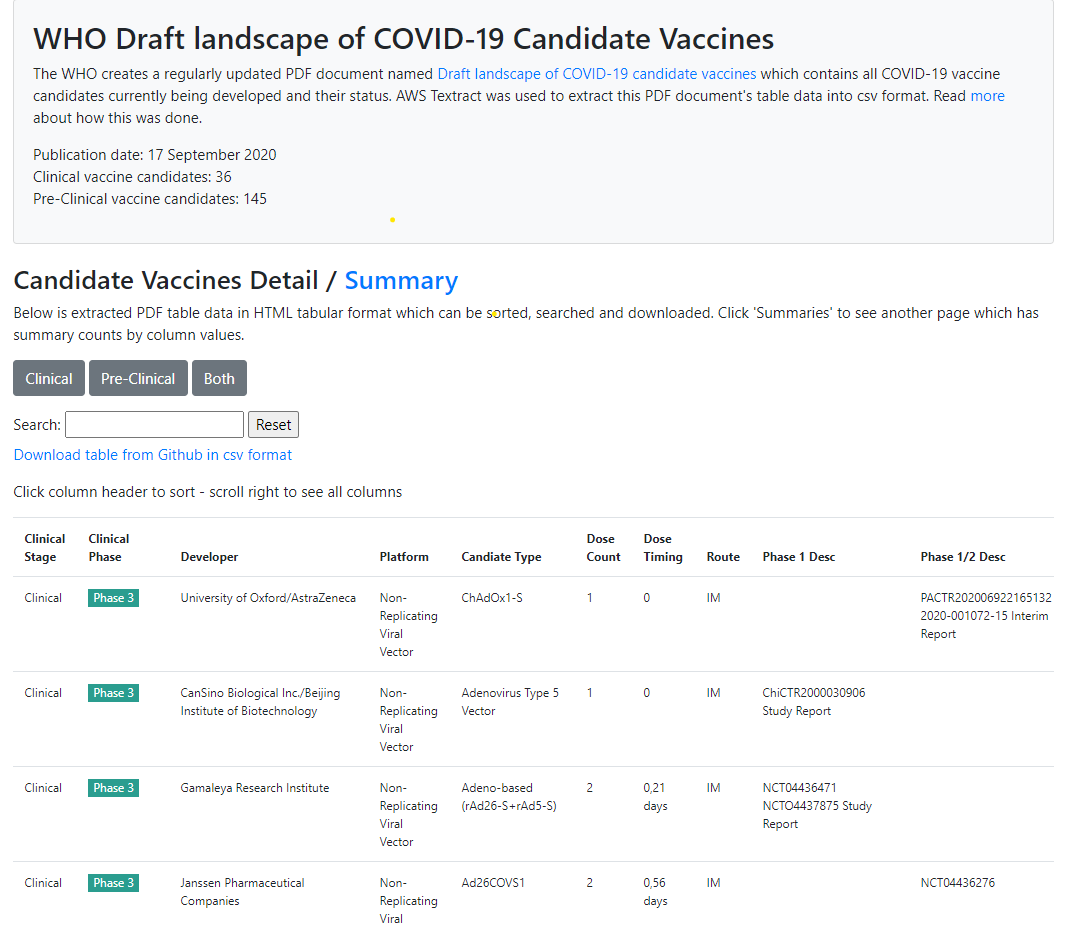
TLDR: I extracted text from the WHO’s vaccine candidate PDF file using AWS Textract and made text into a set of interactive web pages . View the AWS Textract PDF extract output csv files in this Github repository and view and interact with the web pages here.
The World Health Organization (WHO) maintains a regularly updated PDF document named Draft landscape of COVID-19 candidate vaccines which contains all COVID-19 vaccine candidates and treatments currently being developed and their status.
2020-01-03 EDIT: Note that the WHO is now providing an Excel file which contains the same data previously contained in the PDF file referred to in this post.
The main content in this PDF document is a tabular format with one vaccine or treatment per row. There is also some non-tabular text content including introduction text and footer notes.
I wanted a machine readable format version of this PDF document’s table data so I could do some analysis. This meant I needed to do PDF text extraction. There are lots of solutions. I ended up using Amazon Textract to extract the PDF into csv file format.
“Amazon Textract is a service that automatically detects and extracts text and data from scanned documents. It goes beyond simple optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables”
Using Textract
You need an AWS account to use Textract and it does cost to use the service (see costs for this analysis at bottom of post).
The Textract service has UI that you can use to upload and process documents manually eg not using code. However, it is also included in the AWS Boto3 SDK so you can code or use command line automation with Textract too.
I used the manual UI for this one time processing of the PDF. However, if I was to automate this to regularly extract data from the PDF I would use Python and Boto3 SDK. The Boto3 SDK Textract documentation and example code are here.
Use this link to go directly to the AWS Textract UI once you are logged into your AWS console.
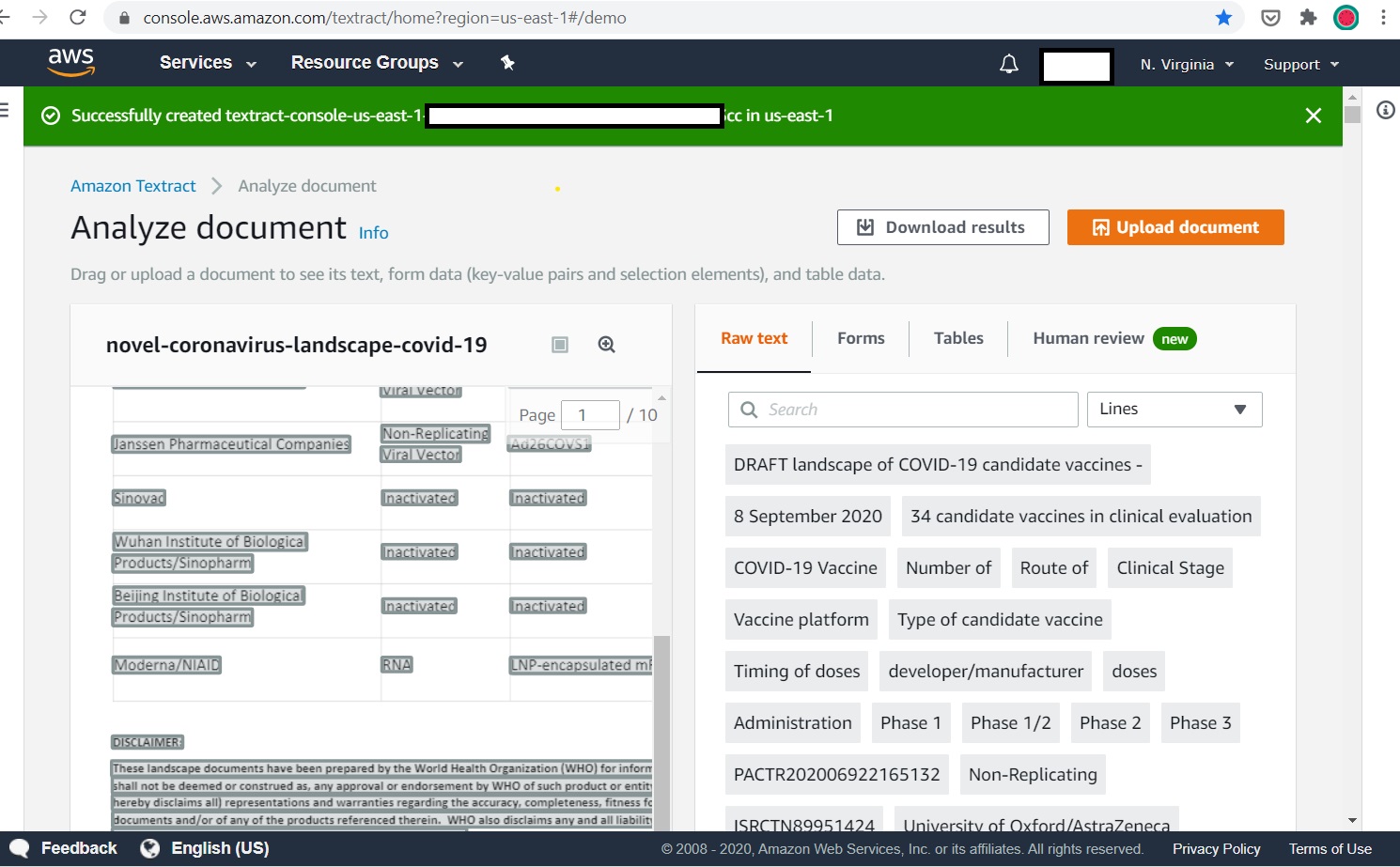
The Textract UI is quite intuitive and easy to use. You manually upload your PDF file, it processes the file and shows you the interpreted content which is described in “blocks” of text, tables, images, and then you can select which to extract from document.
During this process the the manual Textract process asks permission to create a new S3 folder in your account where it uploads the PDF before processing it. This is because Textract will only accept documents from S3.
Screenshot of Textract UI
The Textract PDF extract output is a zip file contained bunch of files that is automatically downloaded to your computer. The zip file contained the files listed below.
These 3 files appear to be standard information for any AWS Textract job.
-
- apiResponse.json
- keyValues.csv
- rawText.txt
The rest of the AWS Textract output will vary depending on your document. In this case it returned a file for each table in the document.
-
- table-1.csv
- table-2.csv
- table-3.csv
- table-4.csv
- table-5.csv
- table-6.csv
- table-7.csv
- table-8.csv
- table-9.csv
To process the AWS Textract table csv files , I imported them into a Pandas dataframe. The Python code used is in Github.
There was some minor clean-up of OCR/interpreted tabular data which included stripping trailing white spaces from all text and removing a few blank table rows. In addition the PDF tables had two header rows that were removed and manually replaced with single header row. Also there were some minor OCR mistakes for example some zeros were rendered as capital letter ‘O’ and some words were missing last letter.
The table columns in the *WHO Draft landscape of COVID-19 candidate vaccines* PDF document tables are shown below. Textract did a good job of capturing these columns.
Vaccine columns:
-
- COVID-19 Vaccine developer or manufacturer
- Vaccine platform
- Type of candidate vaccine
- Number of doses
- Timing of doses
- Route of administration
- Stage – Phase 1
- Stage – Phase 1/2
- Stage – Phase 2
- Stage – Phase 3
Treatment columns:
-
- Platform
- Type of candidate vaccine
- Developer
- Coronavirus target
- Current stage of clinical evaluation/regulatory -Coronavirus candidate
- Same platform for non-Coronavirus candidates
Cost for procesing 9 page PDF file 3 times:
I copied the costs from AWS Billing below to give readers some idea of what Textract costs.
Amazon Textract USE1-AsyncFormsPagesProcessed $1.35
AsyncPagesProcessed: 0-1M pages of AnalyzeDocument Forms, $50 USD per 1000 pages 27.000 pages $1.35
Amazon Textract USE1-AsyncTablespages Processed $0.41
Asyncpages Processed: 0-1M pages of AnalyzeDocument Tables, $15 USD per 1000 pages 27.000 pages $0.41
Amazon Textract USE1-SyncFormspages Processed $0.30
Syncpages Processed: 0-1M pages of AnalyzeDocument Forms, $50 USD per 1000 pages 6.000 pages $0.30
Amazon Textract USE1-SyncTablespages Processed $0.09
Syncpages Processed: 0-1M pages of AnalyzeDocument Tables, $15 USD per 1000 pages 6.000 pages $0.09
HTML tabular presentation of Textract output data
View it here.