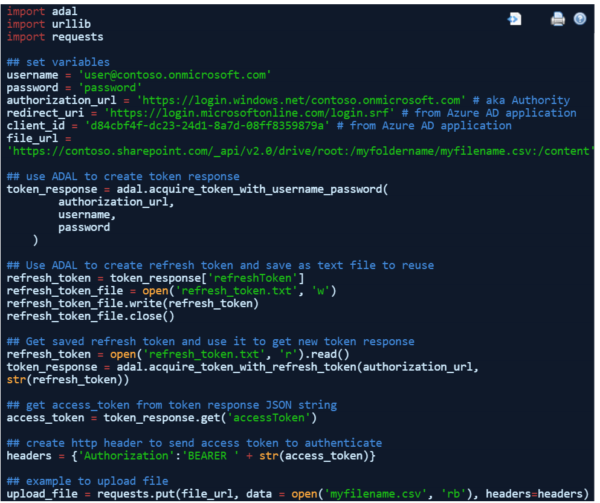
Django recreate database table
Django’s makemigrations and migrate commands are very useful to update existing database tables to reflect model changes. However if you have made many existing table column name changes, migrate will ask you a series of ‘y/N’ questions about which column names are changed. This can be tedious to cycle through especially if there are many […]
Django recreate database table Read More »