
I have created my own historical reporting of my Twitter account followers and list memberships. I have hosted the reporting on this open webpage.
Most people know what followers are but the list memberships aren’t as well known so here are definitions of them.
Twitter Followers – Twitter followers are other Twitter accounts who follow my account. A Twitter Follower may follow my account for a few days and then unfollow me at any time afterwards.
Twitter List Memberships – Twitter accounts can also create their own Lists and then add other Twitter accounts to the lists. For example a Twitter account may create a List called “Tweet about Big Data” to track Twitter accounts they believe “Tweet about Big Data”. Twitter accounts may add my account to their List and remove it at any time afterwards.
The Twitter data retrieval, writing to database, and data querying are all done on a web server.
In order to record changes in counts of these you need to have daily historical data. The Twitter API doesn’t provide historical data so you need create it yourself by retrieving and saving daily data somewhere.
Three Python scripts using Twitter API, Python Tweepy and AWS SDK are scheduled to run daily using cron jobs.
Two scripts retrieve followers and list memberships and insert the data into a PostgreSQL database. This daily retrieval builds the daily history.
Another script queries the database table to create reporting datasets of new, active and dropped followers and list memberships that are exported as csv files to a AWS S3 folder which also has files for a AWS S3 hosted static website.
The AWS S3 hosted static website uses Chart.js and D3.js Javascript charting libraries to read and visualize the data. This post does not describe how to read the csv files but I have written another post that describes this AWS S3 csv file as D3 report data source
Screenshots of visualizations are shown below.
Daily Follower Counts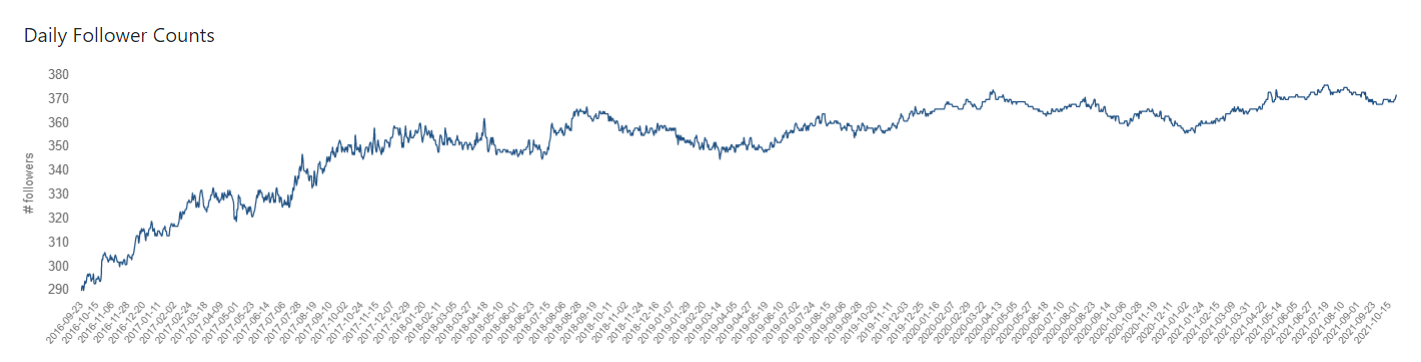
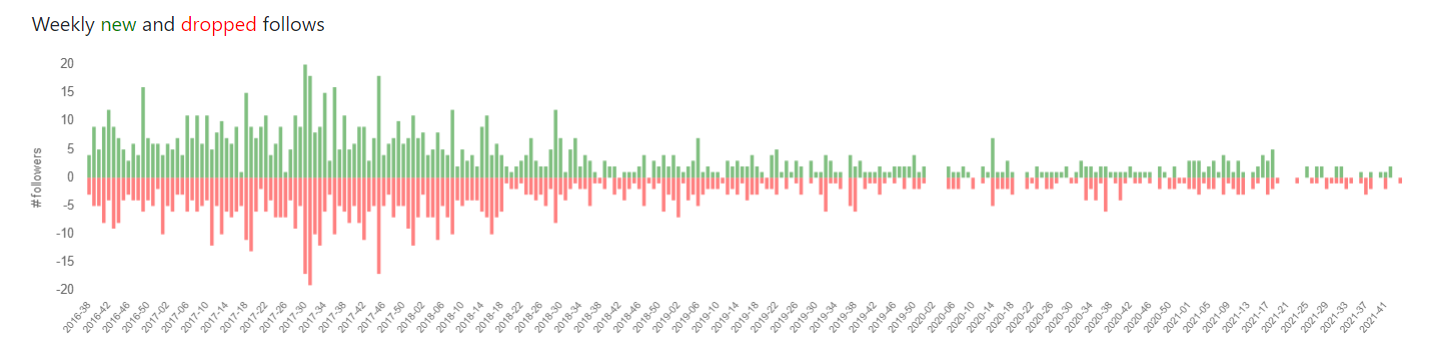
Weekly New and Dropped Follow Counts
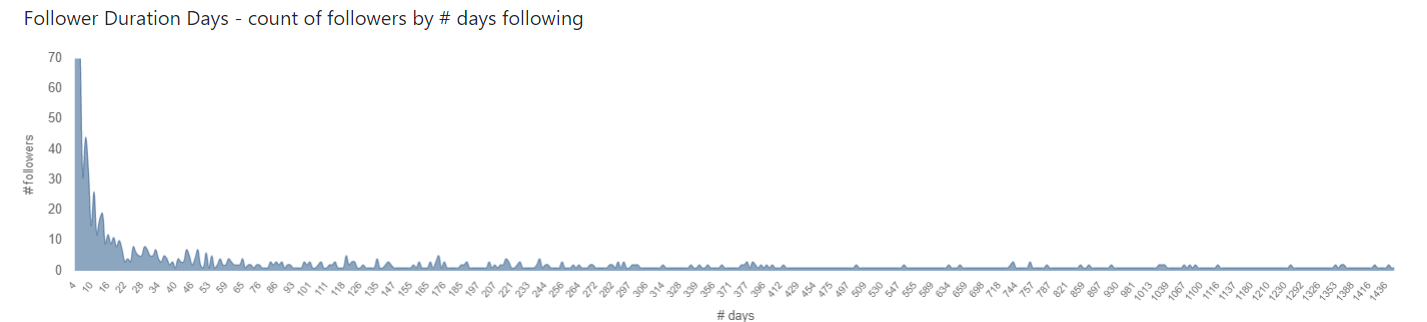
Follower Duration Days
The Python code to retrieve the Twitter data, transform it and create csv files and upload them to AWS is below.
The code to retrieve Twitter followers:
import sys, os
import csv
from datetime import datetime, date
import tweepy
from dateutil import tz
import psycopg2
## get secrets
sys.path.insert(0, '/home/secrets/')
from secrets import secrets
from twitter_keys_tokens import twitter_api_keys
conn = psycopg2.connect(
host = secrets['host'],
dbname = secrets['dbname'],
user = secrets['user'],
password = secrets['password']
)
cursor = conn.cursor()
## twitter consumer key and secret
consumer_key = twitter_api_keys['consumer_key']
consumer_secret = twitter_api_keys['consumer_secret']
#get twitter auth
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
today = datetime.now().date()
def get_followers():
twitter_followers = []
for user in tweepy.Cursor(api.followers, screen_name="twitterusername").items():
twitter_followers.append(user)
for user in twitter_followers:
query = "INSERT INTO twitter_followers \
(date, \
follower_id, \
name, \
screen_name) \
VALUES \
(%s, %s, %s, %s)";
data = (today,
str(user.id).strip(),
str(user.name.encode('utf8','ignore')).replace(',','').strip(),
str(user.screen_name.encode('utf8','ignore')).strip()
)
cursor.execute(query, data)
conn.commit()
conn.close()
## print job status to log
print str(datetime.now()) + ' twitter followers'
if __name__ == '__main__':
get_followers()
The code to retrieve Twitter list memberships:
import sys, os
import csv
from datetime import datetime, date
import tweepy
from dateutil import tz
import psycopg2
## get database creds
sys.path.insert(0, '/home/secrets/')
from secrets import secrets
from twitter_keys_tokens import twitter_api_keys
conn = psycopg2.connect(
host = secrets['host'],
dbname = secrets['dbname'],
user = secrets['user'],
password = secrets['password']
)
cursor = conn.cursor()
## twitter consumer key and secret
consumer_key = twitter_api_keys['consumer_key']
consumer_secret = twitter_api_keys['consumer_secret']
#get twitter auth
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
today = datetime.now().date()
def get_list_memberships():
twitter_list_memberships = []
for list in tweepy.Cursor(api.lists_memberships, screen_name="twitterusername").items():
twitter_list_memberships.append(list)
#print list.full_name
for list in twitter_list_memberships:
query = "INSERT INTO twitter_list_memberships \
(date, \
id_str, \
name, \
full_name, \
member_count, \
subscriber_count, \
mode, \
following, \
user_screen_name) \
VALUES \
(%s, %s, %s, %s, %s, %s, %s, %s, %s)";
data = (today,
list.id_str.encode('utf8','ignore'),
list.name.encode('utf8','ignore'),
list.full_name.encode('utf8','ignore'),
list.member_count,
list.subscriber_count,
list.mode,
list.following,
list.user.screen_name.encode('utf8','ignore'))
cursor.execute(query, data)
conn.commit()
conn.close()
## print status for log
print str(datetime.now()) + ' twitter list memberships'
if __name__ == '__main__':
get_list_memberships()
The code to create csv files and upload to AWS S3 bucket:
from boto.s3.connection import S3Connection
from boto.s3.key import Key
from datetime import datetime
from os import listdir
from os.path import isfile, join
import sys
import csv
import psycopg2
import re
from collections import Counter
upload_path = '/home/twitter/aws_s3_site/'
sys.path.insert(0, '/home/secret/')
from aws_keys import aws_keys
from secrets import secrets
## create aws S3 connection
conn = S3Connection(aws_keys['AWS_KEY'], aws_keys['AWS_SECRET'])
bucket = conn.get_bucket('twitter-bucket', validate=False)
## create db connection
conn = psycopg2.connect(
host = secrets['host'],
dbname = secrets['dbname'],
user = secrets['user'],
password = secrets['password']
)
cur = conn.cursor()
## get data sets from db
## followers
cur.execute ("select something here;")
followers = list(cur.fetchall())
## lists
cur.execute ("select something here;")
lists = list(cur.fetchall())
conn.close()
## write db data to csv files, save in upload folder
## followers
with open(upload_path + 'followers.csv', 'wb') as file:
writer = csv.writer(file, delimiter = ',', lineterminator='\n')
for row in followers:
writer.writerow(row)
## lists
with open(upload_path + 'lists.csv', 'wb') as file:
writer = csv.writer(file, delimiter = ',', lineterminator='\n')
for row in lists:
writer.writerow(row)
## upload csv files to S3 twitter-bucket
upload_files = [f for f in listdir(upload_path) if isfile(join(upload_path, f))]
# delete existing bucket keys to reset
for key in bucket.list():
if '.csv' in key:
bucket.delete_key(key)
# complete uploading to AWS
for file in upload_files:
k = Key(bucket)
k.key = file
k.set_contents_from_filename(upload_path + file)
## write success to cron log
print str(datetime.now()) + ' aws s3 twitter upload'
HI Curtis,
This is an amazing post!
I was wondering if you had, by any chance, posted the Python code somewhere!
I am trying to learn more about Twitter APIs and this would be an amazing personal project!
Thank you for your help,
Matteo from Italy
HI Curtis,
This is an amazing post!
I was wondering if you had, by any chance, posted the Python code somewhere!
I am trying to learn more about Twitter APIs and this would be an amazing personal project!
Thank you for your help,
Matteo from Italy
Thanks Matteo. I haven’t gotten around to including the Python code in this site.
But check out other posts I have that include Twitter API Python code that might be interesting for you too!
http://009co.com/?p=508
http://009co.com/?p=215
http://009co.com/?p=278
I have learned most of what I need to use the Twitter API through searching other people’s blogs and StackOverflow. I have had to modify almost all of the code on my own though once I found other people’s code.
Conceptually it is pretty straightforward but the details as always make it a bit more challenging.
First you need Twitter Developer account which can be same user as any regular Twitter account. Then you need to create API keys that will uniquely identify you to the Twitter API. Depending on what you are doing you may also be required to setup authentication.
I recommend using Tweepy which is Python module that is made to interact with Twitter API. You then have to just learn how to use Tweepy rather than interact with Twitter API directly which makes it easier.
Good luck!